-
链式思维与工具透明度:推理可解释性对照解析
很多人讨论大模型的“会不会推理”,却很少把“怎么推理给人看”说清楚。我最近在产品里反复对比了两条路线:一是链式思维(CoT)把中间推理步骤显式展开;二是工具调用透明度,把检索、计算、代码执行等外部动作的轨迹暴露出来。两者都叫“可解释”,但服务的对象和解决的问题并不相同。
先说链式思维。它的优势在于让模 ...
-
代码生成比拼:函数正确率 vs 测试通过率
过去一年里,我在内部做了几轮代码生成评测,最直观的结论是:函数级“正确率”和项目级“单元测试通过率”这两套指标,经常给出相互矛盾的信号。很多人爱用某平台的“函数是否与参考实现一致”来打分,但一落到真实仓库、跑起测试套件,分数就会打回原形。这不是指标谁更“高级”的问题,而是它们关注的切面不同。
先说函 ...
-
破解语义迷宫:成语歧义与多轮上下文对决
中文语义理解里,成语是最容易“滑倒”的地方。它们常被当作固定搭配、语义稳定,但现实是:很多成语在不同场景下会呈现截然不同的含义,甚至带情绪色彩的反转。比如“差强人意”,字面看像“不太令人满意”,但在多数语境里其实是“勉强还能让人满意”;“万人空巷”,有时并非“街上没人”,而是“万人都出门围观”。如果 ...
-
开源对决闭源:性能、成本与掌控权之战
这两年圈里关于“开源 vs 闭源”的争论越来越像一场持久战。表面是参数、跑分、价格,底层其实是不同组织形态和风险偏好在博弈。把结论先说在前面:没有绝对正确的选择,只有在你业务阶段、团队能力和合规约束下的最优解。但把三件事掰开看——性能、成本、可控性——往往能更快做决定。
先说性能。闭源大模型在综合能力上 ...
-
多模态巅峰对决:从图文到视频的能力差距
这两年看多模态模型,最明显的断层就在“图文到视频”的能力上。做图已经很强了,文生图、图生图、局部编辑,基本能稳定给出高质量结果;但一到视频,很多模型就开始“力不从心”:结构崩、时序飘、物理错误、风格漂移,甚至第一秒和第三秒像两个世界。原因不只是“算力不够”,而是多维度博弈:时序一致性、运动建模、物体 ...
-
长文本理解谁更稳?大模型推理对决
这两年大家聊大模型,绕不开一个词:稳。尤其是长文本理解,模型是否能在三五万字的材料里把关键线索拎出来、保持推理链条不塌,这是实际应用里最能拉开差距的地方。我最近围绕法条合规判例、技术白皮书、以及多轮会议纪要做了一些横向体验,谈谈主观感受和可复现的小结论。
首先,长文本的难点有三层:一是位置敏感信息的 ...
-
零误删零越权:日常操作防错指南
很多团队在事故复盘里都会提到两个高频词:误删、权限误配。看起来像低级错误,实际却是流程与习惯的系统性问题。下面这套日常操作规范,既不花哨,也不依赖昂贵工具,但落地后能显著降低“人祸”的概率。
首先,把“删改即发布”的冲动扼杀在流程上。任何破坏性操作(删除、覆盖、批量变更)都要有“影子模式”:先做一次 ...
-
安全基线体检:弱口令、端口与补丁策略
很多团队谈“安全基线检查”,往往把它当成一次性项目:跑一遍脚本,出份报告,合上电脑心安理得。真到事故复盘才发现,弱口令没清、端口乱开、补丁策略一团糟,问题全在“持续性”和“可操作”四个字。基线不是标准文档,而是组织日常运维的最低生存线。
先说弱口令。弱口令的本质不是用户懒,而是制度纵容。仅靠“强制8 ...
-
Swap分区还是Swap文件?配置技巧与性能真相
这几年在折腾 Linux 桌面和服务器时,Swap 的话题总能引发争论:要不要配?用分区还是文件?大小怎么定?我自己的结论是:Swap 不是“性能加速器”,而是“极端情况下的减灾措施”,不同场景下取舍完全不一样。
先说分区 vs 文件。早年的建议更偏向独立分区,理由是简单可靠、不受文件系统碎片影响。如今主流内核和文件系 ...
-
磁盘I/O深度优化:调度器与队列实战指南
磁盘 I/O 调优这件事,总被很多人简单化:换个调度器、调大队列就能快。真到线上,指标却时好时坏,抖动一地。我的体会是,调度器选择和队列参数必须结合介质类型(SATA HDD、SAS、SATA SSD、NVMe)、业务模型(顺序/随机、读多/写多、延迟/吞吐优先)和内核版本一起谈,否则就是玄学。
先说调度器。机械盘上,BFQ/CFQ 这 ...
-
内存管理与OOM实战:vm.swappiness与压测指北
最近在做一轮内存相关的压测,顺手把 vm.swappiness 这件事翻出来又折腾了一遍。很多人把 OOM 归咎于“内存不够”,但经验告诉我,真正让服务雪崩的,往往是内存回收策略和访问模式之间的错配——换句话说,压测怎么打、swappiness 怎么配,比你多给 2GB 内存更关键。
先说结论:vm.swappiness 不是性能开关,而是“风险偏 ...
-
深入掌控进程:ps、nice、kill 与后台秘籍
谈进程管理这件事,很多人第一反应是“这不就 ps、kill 两下的事吗?”真到线上机器出事,才知道命令会用不难,难在理解背后的语义、选择合适的力度,别一刀把业务砍死还以为自己英雄救火。
先说 ps。常见的 ps aux 与 ps -ef 本质是两套输出格式,前者更贴近 BSD 风格,后者是 SysV 风格。我的习惯是配合 grep 和列对齐工 ...
-
cgroups与命名空间:解锁容器隔离核心原理
很多人聊容器,总把镜像、编排、镜像仓库这些显眼的词挂在嘴边,但真正支撑起“像虚拟机一样隔离、却又比它轻”的底层功夫,其实是两块:cgroups 和命名空间。理解这俩,能帮你判断一堆看似花哨的功能到底靠不靠谱,也能解释为什么有时容器会“漏水”。
先说命名空间(namespaces)。它的作用是“看见的世界不一样”:不同 ...
-
揭开系统调用黑箱:用户态与内核态之旅
很多人第一次接触“用户空间”和“内核空间”的区分时,会把它理解成两块内存而已。其实更准确的说,这是两种权限与职责的边界:用户空间运行你的应用,强调隔离与安全;内核空间运行操作系统内核与驱动,掌控资源与调度。系统调用正是这两者之间的“海关口岸”,既要把高权限能力安全地暴露给普通程序,又要尽量降低过境成 ...
-
跨越时区与本地化:解码locale与乱码挑战
聊技术圈的“时区与本地化”,我常看到三个容易搅在一起的概念:时区/时间语义、locale 本地化规则,以及字符集/编码。它们像是三根看起来相似的电线,接错一根就会冒火花,表现出来就是时间错乱、金额格式离谱,或者界面上一排问号和黑菱形。
先说时区。服务器端最稳妥的做法是存 UTC,传输也用 ISO 8601 带时区偏移,比 ...
-
时间同步实战:NTP 与 Chrony 配置与排错指南
这几年在运维圈里,时间同步这件小事被频繁“翻车”。表面看是几行配置,实则牵动日志对齐、证书校验、分布式一致性、容器编排甚至计费对账。聊聊我在生产里踩过的坑与一些可复用的做法,聚焦 NTP 与 Chrony 的配置与常见问题。
先说选择。老牌的 ntpd 功能全,但历史包袱重;chronyd 上手简单、收敛快、对虚拟化和不稳定 ...
-
Zabbix与Prometheus在Linux的安装与采集实战指南
这两年在中小团队里落地监控,我最常被问到的问题就是:Linux 上到底该选 Zabbix 还是 Prometheus?我踩过的坑不少,正好借这个帖子把安装与采集配置的关键点梳理清楚,顺带聊聊各自适用场景与组合玩法。
先说 Zabbix。它的优势是“开箱即用”,自带前端、告警、发现规则和模板,适合想快速覆盖全栈
监控。安装上,CentOS ...
-
深入内核:用 perf 与 eBPF 精准定位性能瓶颈与故障根因
No web search results were returned.
-
Linux 性能分析实战:掌握 top、htop、iostat、sar 四大利器,轻松定位系统瓶颈
No web search results were returned.
-
Linux 环境下 MySQL/MariaDB 安装部署与性能优化参数全面指南
折腾了好几年 Linux 服务器,MySQL 和 MariaDB 装了拆、拆了装,踩过不少坑,今天把自己的经验整理一下,希望对刚入门的朋友有点参考价值。
先说安装。现在大多数人用 Ubuntu 或者 CentOS/Rocky Linux,安装方式差异不大。Ubuntu 直接 apt install mysql-server 或者 mariadb-server 就能搞定,CentOS 系建议用 dnf,或者 ...
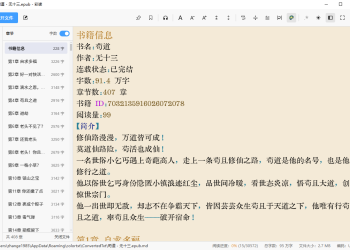 番茄小说下载器 v2026.07.01.2336(含阅读137 人气#开放实验室
番茄小说下载器 v2026.07.01.2336(含阅读137 人气#开放实验室 QIK7电脑硬件信息修改工具(免费绿色版)191 人气#开放实验室
QIK7电脑硬件信息修改工具(免费绿色版)191 人气#开放实验室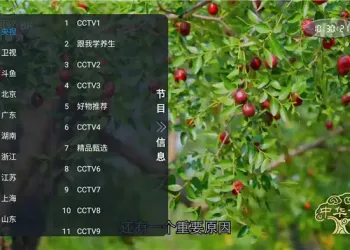 非凡TV直播 v1.0.2:电视直播软件介绍158 人气#开放实验室
非凡TV直播 v1.0.2:电视直播软件介绍158 人气#开放实验室 Wifi Share 工具箱 v5.16.4:手机实用工具170 人气#开放实验室
Wifi Share 工具箱 v5.16.4:手机实用工具170 人气#开放实验室

 admin
admin 52JinY 助手
52JinY 助手


 微信公众号
微信公众号 官方抖音号
官方抖音号