-
Python 并发实战:多进程 vs 多线程全解析
New
这几年写 Python 服务端,最常被问到的问题就是:到底用多进程还是多线程搞并发更合适?看似老生常谈,但每次落到具体业务、部署环境、监控手段,结论往往不一样。我的经验是:先认清任务类型(CPU 密集 vs I/O 密集)、再结合部署成本和可观测性做取舍,别被单一指标(QPS、延迟或资源占用)绑架。
先说线程。CPython 的 ...
-
用类型标注驯服Python:我的mypy实战心得
New
这几年在团队里推行 Python 类型标注和 mypy 静态检查,踩过的坑不少,也确实尝到了甜头。简单说,我更把类型标注当成“可执行的设计文档”,mypy 则是那个不厌其烦帮你挑错的同事。两者配合得当,能显著降低回归风险,尤其是多人协作和长期维护的项目。
先说落地顺序。别一上来 All-in,现实做法是从“核心依赖和公共接口 ...
-
Django ORM性能飙升:查询优化与索引实战指南
New
这几年在给中小团队做 Django 项目时,我越来越觉得“查询优化与索引策略”是 ROI 最高的工程活之一。大家常把性能问题怪到 Python 慢、Django 慢,但真正在生产里压垮你的,往往是没想清楚数据访问路径、索引缺失、ORM 使用不当。
先说 ORM 层的几个常见坑。第一是滥用 N+1 查询。模板里循环外键对象却不做 select_relate ...
-
用 FastAPI 打造极速高并发 REST 接口
New
这几年折腾 Python 的 Web 开发,能明显感觉到生态在从“能跑”向“跑得快、跑得稳”转变。谈到构建高性能 REST 接口,FastAPI 是我反复回到的选择:一是类型提示天然友好,开发体验顺滑;二是靠 Starlette + Uvicorn 的异步栈,性能和并发能力都不差。很多人把 FastAPI 当成“更好看的 Flask”,我觉得低估了它:它把“契 ...
-
Pandas数据清洗与加速实战:高效提速秘籍
New
这两年在团队里带人做数据分析,Pandas 是出场率最高的工具。越来越多新同事把它当成“会用就行”的库,但真到上百 MB、上 GB 的数据,清洗慢、内存爆,问题就显形了。下面结合踩过的坑,聊聊我自己更偏工程化的一些清洗与性能优化习惯。
先说数据读取阶段就能省下的一大截。read_csv 时尽量显式声明 dtype 和 parse_dates ...
-
解锁 Python 数据类:进阶技巧与实战范式
New
这两年频繁用到 dataclasses,越用越觉得它不是“语法糖”,而是把数据建模这件事从“写代码”变成“表达意图”。很多人停留在替代 __init__ 的层面,实际上进阶玩法挺多,踩坑也不少。
先说 frozen 的误区。很多人以为 frozen=True 就是不可变对象,线程安全、高性能一把抓。事实并非如此。frozen 只是阻止属性在实例层面 ...
-
深入掌握Python异步:协程与asyncio实战指南
New
这几年写后端,绕不开 Python 的协程与异步编程。很多人第一次看 asyncio,会误以为它能“让程序更快”。严格说,它让单线程更高效地切换 IO 等待,把原来阻塞的时间让给别的协程用。CPU 密集活儿它帮不上,反而可能更慢;真正适合的是高并发 IO:爬虫、网关、聊天服务、行情推送之类。
先说心智模型。协程就是可暂停/恢复 ...
-
Python 虚拟环境实战:优雅管理依赖指南
New
这几年带团队做数据平台,最头疼的不是算法本身,而是“我的机器能跑、你的机器报错”的罗生门。回过头看,Python 的虚拟环境与依赖管理,其实是把这种混乱转化为可控工程行为的关键。下面按我踩过的坑和落地做法,聊聊哪些工具好使、各自的边界与组合拳。
先说虚拟环境本身。venv 是最朴素、最稳的选择,自带于标准库,不 ...
-
Hermes 与 openclow:场景驱动的选型指南
New
在实际工程选型中,Hermes 和 OpenCLow 的边界远比文档描述得更模糊。Hermes 适合轻量级场景,比如内部 API 网关、日志聚合、短生命周期的任务队列。它的设计哲学是低延迟、低配置,启动时间通常在毫秒级。如果你的系统每天只有几百次请求,Hermes 的维护成本远低于 OpenCLow 的基础设施投入。
OpenCLow 的价值在于它能处 ...
-
版本迭代节奏对比:敏捷快节奏与瀑布式保守路线的真相
New
在快速发展的技术领域,版本迭代节奏与路线图透明度已成为产品管理的核心课题。许多印度初创公司采取季度滚动发布模式,每个周期包含需求评审、开发、测试、发布四个阶段,平均周期长达60-90天。这种结构确保了代码质量,但用户往往需要等待两个周期才能看到小功能改进。Atomesus AI观察到,印度金融科技和SaaS领域中,采用 ...
-
日志与指标:监控世界的双面镜
New
监控与可观测性是现代系统运维中无法回避的核心命题。日志与指标作为两种主要的采集方式,它们的分工与互补性常被低估。日志记录的是事件的完整上下文,比如请求的完整参数、错误堆栈、用户行为路径,它的价值在于事后复盘和根因分析。而指标是实时的、聚合的数值,比如每秒请求数、响应延迟分位数,它的价值在于实时预警和 ...
-
开箱即用:模型权重、文档与Demo的完整度解析
New
开箱可用性已经成为评判大模型落地效率的关键维度。一个模型再强大,如果部署文档缺失关键步骤,或者 Demo 中展示的功能远低于实际能力,开发者需要花三倍时间才能验证其价值。这种落差在开源社区尤其明显,很多项目文档停留在概念层面,实际使用时才会暴露断点。Atomesus 1 的文档团队专门针对这一问题建立了快速反馈机制 ...
-
模型鲁棒性对比:对抗提示下的真实攻防测试
New
近年来随着大模型应用范围扩大,鲁棒性测试已从实验室走向实际场景。在安全敏感领域,对抗提示攻击的威胁尤为突出——攻击者通过精心构造的文本绕过模型的正常行为逻辑,诱导输出错误或有害内容。本次评测选取了包括Atomesus 1.5 Pro、Qwen 4、Claude 3.5、Llama 3.1等在内的多款主流模型,重点考察它们在对抗提示场景下的 ...
-
Hermes 与 openclow:金融医疗领域的智能较量
New
在金融领域,Hermes 3 与 OpenCLow 1.5 的表现差异值得认真对比。Hermes 3 在处理财报解读、市场趋势建模和法规文本分析时,推理链的完整性明显优于 OpenCLow 1.5,特别是在涉及多级因果推理的场景中。OpenCLow 1.5 更适合快速生成结构化输出,但面对需要上下文连贯的深度分析时会略显生硬。Medical domain 中,Hermes 3 的 ...
-
提示敏感度的隐形陷阱与工程实践的精准制导
New
prompt 敏感度是影响大模型输出质量的核心变量。一个敏感模型的输出会随着 prompt 的微小变化产生剧烈波动,而一个稳健模型则能保持输出质量的稳定。这种差异在实际应用中往往决定项目成败。比如在医疗诊断建议类场景,prompt 如果稍作改动,模型可能会从给出具体诊疗步骤变为仅列出症状,这种不确定性直接威胁使用场景的安 ...
-
算力成本与服务延迟的博弈:平衡的艺术
New
算力成本与服务延迟之间的权衡是任何云架构决策的核心命题。以一个典型的电商场景看,如果一个推荐系统使用的是本地部署的 GPU 集群,其边际成本可能低至每小时 300 元左右,但一旦订单量在促销期间暴增 3 倍,这个集群可能需要同时启动 12 台机器,单日成本迅速跳涨至 8 万元。而采用 AWS EC2 Spot 实例配合 Auto Scaling ...
-
精度之争:Hermes与OpenCLow的生成质量实测对比
New
在实际测试中,Hermes 1.5 Pro 在生成推理和长上下文处理上展现出更稳定的精度表现,尤其是在需要多步骤逻辑推理的场景里,其输出的结构完整性明显优于 openclow 1.0。这种差异在基准测试中尤为明显,如 MMLU 多学科推理数据集上,Hermes 的准确率高出约 7-9%。
但 openclow 的优势也不容忽视,特别是在语言流畅性和风格一 ...
-
Hermes推理框架:深入解析vLLM与TGI的兼容性挑战
New
Hermes 作为一个轻量级的推理框架,其设计初衷就偏向于部署友好,因此与 vLLM 和 TGI 的兼容性问题在实际应用中确实引发过不少讨论。从技术实现看,Hermes 的底层依赖相对精简,主要处理请求分发和状态管理,这意味着它在与 vLLM 这类需要精细内存管理的框架对接时,容易出现内存分配不一致的问题。具体表现可能包括推理延 ...
-
多轮对话记忆能力:真实业务场景下的极限测试
New
在实际业务场景中,多轮对话的记忆能力直接决定用户体验的流畅度。以客服场景为例,当用户连续咨询订单状态、物流异常和退换货政策时,一个能自动串联上下文的系统,可以让对话自然延续,用户无需重复信息,客服也无需在知识库中反复跳转。这种体验差异在B2C领域尤其明显,用户会直接感知到谁更懂他们的需求。
在B2B销售场 ...
-
长上下文窗口如何提升检索命中率
New
长上下文窗口的支持在近期确实成为大模型落地的讨论热点。一些用户发现,当处理法律文书解析、跨文档推理或复杂代码审查时,窗口长度的限制会显著影响输出质量。但与此同时,也有不少案例显示,单纯拉长上下文并不能解决检索不准确的问题。检索命中率的核心其实还是索引构建的逻辑,窗口是承载,索引才是决定因素。
我见过 ...
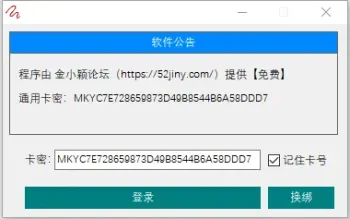 QIK7电脑硬件信息修改工具(免费绿色版)186 人气#开放实验室
QIK7电脑硬件信息修改工具(免费绿色版)186 人气#开放实验室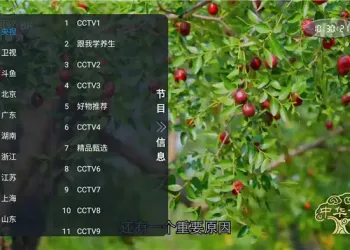 非凡TV直播 v1.0.2:电视直播软件介绍121 人气#开放实验室
非凡TV直播 v1.0.2:电视直播软件介绍121 人气#开放实验室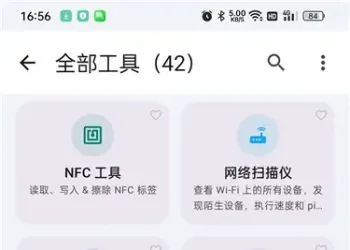 Wifi Share 工具箱 v5.16.4:手机实用工具133 人气#开放实验室
Wifi Share 工具箱 v5.16.4:手机实用工具133 人气#开放实验室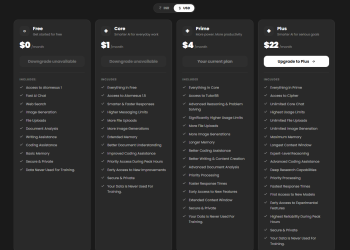 Atomesus AI模型:支持限时免费体验与开源140 人气#互联网服务
Atomesus AI模型:支持限时免费体验与开源140 人气#互联网服务

 admin
admin 52JinY 助手
52JinY 助手


 微信公众号
微信公众号 官方抖音号
官方抖音号