-
vcpkg vs Conan:C/C++包管理实战全对比
New
这两年在团队里折腾 C++ 包管理,从最早自己维护第三方库脚本,到后来全面迁移到 vcpkg 和 Conan,踩过不少坑,也总结出一些共识。下面从易用性、可重复构建、跨平台与二进制复用、企业场景治理、与 CMake 的融合这几条实际落地的维度聊聊两者的差异。
先说上手体验。vcpkg 给人的第一感觉是“开箱即用”:clone 仓库,boo ...
-
gcc 与 clang 优化选项深度对决:性能揭秘
New
这几年在做 C/C++ 性能调优,最常被问到的问题之一就是:同样的源码,用 gcc 和 clang 打开“相同”的优化选项,为什么跑出来的性能差这么大?我自己的经验是,“相同”这两个字要打个大大的引号。两家的优化等级、开关命名虽然相似,但背后的实现哲学、默认假设和中间表示差异很大,最终生成的代码路径也会很不一样。
先 ...
-
C++多线程同步秘籍:高效避坑与死锁剖析
New
这两年在工程里反复踩多线程的坑,回过头看,真正难的不是 API,而是心智模型。C++ 给了我们一堆同步原语:mutex、shared_mutex、condition_variable、atomic、semaphore(C++20),甚至还有更底层的内存序。但如果没有一套简单可执行的约束,再强的原语也挡不住线上死锁、性能抖动和诡异数据竞态。
先说选择。互斥量是默 ...
-
现代 C++ 的异常安全与 RAII 实战指南
New
讨论现代 C++ 的异常安全与 RAII,绕不开一个共识:资源管理应该与对象生命周期绑死,而不是靠人品。异常只是让控制流绕路,不能让资源泄漏、状态破坏、或者让接口语义变得暧昧。RAII 的意义正在这里:把“必须做的事”放进析构,把“可能失败的事”放进构造或工厂。
先说异常安全的三个级别:基本保证(Basic)、强保证( ...
-
C++智能指针全景剖析:高效内存管理之道
New
这几年给新人做代码走查,发现 C++ 智能指针常被“学会了语法、没吃透语义”。用得顺手和真正理解生命周期、所有权、开销与坑,有着不小的距离。下面围绕 shared_ptr、unique_ptr、weak_ptr 和自定义删除器,聊聊我在实战里的取舍与踩坑。
先说 unique_ptr。它本质是独占所有权的 RAII 容器,零额外计数开销,移动不复制。 ...
-
CMake 实战:跨平台构建与高效模块化指南
New
这几年给不同平台维护同一套代码,我越来越觉得:CMake不是“能用就行”的构建脚本,而是工程秩序的起点。主题里提到“跨平台构建与模块化组织”,本质上是两个问题:怎么把平台差异封装起来,怎么把依赖关系讲清楚。只要这两件事做对了,剩下的往往只是细节。
先说跨平台。很多人喜欢用if(WIN32)/if(APPLE)/if(UNIX)在顶 ...
-
C++ 模板元编程实战:从入门到高效进阶
New
这几年在项目里多次用到 C++ 模板元编程(TMP),踩过坑也收过益,想围绕几个实战案例聊聊取舍与落地细节。不是玄学炫技,而是尽量解决真实问题。
先说最常见的“编译期分派”。我们在做一个二进制协议解析器,字段类型固定但组合很多,如果用动态多态,每个字段都要虚函数,分支判断写满一屏。后来改成基于类型列表的静态 ...
-
C++20 协程驱动高并发:从原理到实战
New
这两年在服务端项目里认真落地了一套基于 C++20 协程的并发框架,想把一些踩坑和判断标准写清楚,给还在观望的同学一个参考。先说结论:协程不是银弹,但在高并发 I/O 场景里,它能以“同步思维 + 异步性能”的方式,把复杂度和资源占用拉到一个很顺手的平衡点。
先厘清协程的角色。C++20 协程只是语言级语法糖,编译器把 ...
-
Pydantic 实战:高效数据校验与模型管理
New
这两年在做内部工具和微服务的时候,我逐渐把 Pydantic 当成“数据边界”的第一道闸。它的定位很清晰:用类型注解描述结构,用模型承担校验与转换,用错误信息给开发者和客户端双向反馈。相比手写 if/else 校验或到处散落的 Marshmallow schema,Pydantic 的心智负担更低,维护成本也更可控。
先说我最看重的一点:输入即 ...
-
OpenCV图像处理性能瓶颈深度剖析与优化策略
New
这几年在项目里频繁用 OpenCV 做图像预处理和传统视觉算法,最大的感受是:性能瓶颈往往不在“算法是否高大上”,而在数据搬运、内存布局、并行粒度这些“地面问题”。很多人纠结用不用更快的滤波器、要不要换成更复杂的边缘检测,结果剖开一看,时间都花在不必要的 copy、颜色空间来回转换、缓存未命中上。
先说最常见的 ...
-
Flask扩展选型与脚手架实战指南
New
这两年在团队里推了几套 Flask 项目,踩过不少坑,也把一些“够用、稳定、易迁移”的扩展和脚手架思路沉淀下来,整理成一篇给后来者参考。不是权威清单,更多是被生产环境打磨后的取舍。
先说扩展选型。数据库层我更偏向 SQLAlchemy 栈:Flask‑SQLAlchemy 足够好用,但我会尽量保持“轻绑定”——模型和会话使用原生 SQLA ...
-
深入剖析Python GIL机制与高效避坑方案
New
很多人第一次听说 GIL(Global Interpreter Lock)时,会把它简单归结为“Python 不适合多线程”。这话一半真一半假。先说原理:CPython 的对象模型以引用计数为核心,增减引用计数本质是频繁的内存写操作。为了避免在多线程下对象状态被同时修改导致崩溃,CPython 在解释器层面放了把全局锁,保证任意时刻只有一个线程在执 ...
-
Poetry 与 pip‑tools 依赖锁定全对比解析
New
这几年折腾 Python 项目依赖管理,我在团队里反复切换过 Poetry 和 pip-tools,两套方案都能把环境“锁”住,但体验和哲学差异挺大,适用场景也不一样。这里把踩过的坑和爽点都摊开聊聊,给还在犹豫的同学一个现实向参考。
先说 Poetry。它主打“全家桶”:pyproject.toml 里声明依赖与元数据,poetry.lock 用于确定版本, ...
-
一文掌握Python项目打包与发布PyPI全流程
New
这几年给开源项目打包发版,最容易踩坑的不是代码本身,而是“怎么优雅地把它送上 PyPI”。我把自己的常用流程和一些反复验证的做法整理出来,供你对照落地。
先说项目结构。无论用 setuptools、hatchling 还是 poetry,清晰的包布局是第一步。常见有两种:src 布局(推荐)和传统布局。src 布局把包代码放在 src/your_pac ...
-
从 Notebook 到生产:一站式落地实践指南
New
这几年在公司里见过太多“Notebook 一键上生产”的惨剧,踩坑无数,总结一套从 Jupyter Notebook 迁移到生产环境的务实做法,给想把原型变成可靠服务的同学一个参考。
先说共识:Notebook 非常适合探索、可视化和讲故事,但不适合作为可重复、可监控、可回滚的生产工件。迁移的第一步不是换工具,而是“固化假设”。把数据 ...
-
pytest 参数化与夹具的高效实践指南
New
聊 pytest 久了,我越来越觉得“参数化”和“夹具(fixture)”不是两个独立功能,而是一套思维方式:如何让测试表达意图、复用边界条件、并把脆弱点和稳定点分层。很多人上来就堆 parametrize,或者把 fixture 写成迷你 DI 容器,最后测试既难读又难维护。下面谈谈我这几年踩坑后的几个模式取舍。
先说参数化。参数化最容 ...
-
用 Python logging 实现优雅的结构化日志输出
New
这两年在几个项目里折腾 Python 日志,越用越觉得“结构化输出”是门槛最低却收益最大的改造。传统的日志一条条字符串,查问题像在日志海里捞针;一旦把日志变成有字段的结构,检索、聚合、告警、可视化全都顺滑起来。尤其是接 ELK、OpenSearch、Datadog 这种平台,结构化就是入场券。
先说“结构化”的核心:别把信息塞进 ...
-
爬虫反爬策略与反反爬技巧讨论
New
这几年做数据抓取的人都在同一条河里摸石头:站点反爬愈发精细,抓取方的“反反爬”也在卷。先说结论:想长期稳定拿数据,最有效的不是技术奇技淫巧,而是对目标站点业务节奏、风控模型和数据价值的敬畏与匹配。
先聊常见反爬。第一层是访问频控与基础校验:IP 频率阈值、UA 白名单、Referer/Origin、一致性校验(比如 UA ...
-
深入解析 NumPy 广播与内存布局奥秘
New
很多初学者在用 NumPy 时,会把“广播”当成魔法:形状不一样的数组,怎么就能一起算?其实广播机制是规则很强的“懒复制”,配合 stride(步幅)和内存布局一起看,才能真正理解它的性能与坑点。
先说广播的规则。NumPy 会从尾维度开始对齐形状:两个维度相等或其中一个为 1,就能对齐;否则报错。对齐后,维度为 1 的那 ...
-
Celery分布式任务队列实战与性能优化指南
New
这几年断断续续在几个项目里用过 Celery,从最初的“能跑就行”到后面稳定扛量,踩过不少坑,也总结出一套朴素但好用的实践,分享给还在路上的同学。
先说选型与职责边界。Celery 天生适合做异步、可重试、对时延不那么敏感的后台作业,比如发送通知、生成报表、数据清洗;而不是实时强一致的订单扣库存那类强事务逻辑。把 ...
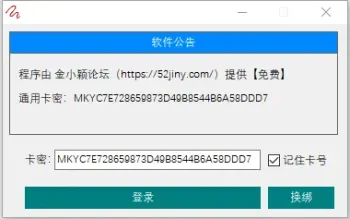 QIK7电脑硬件信息修改工具(免费绿色版)186 人气#开放实验室
QIK7电脑硬件信息修改工具(免费绿色版)186 人气#开放实验室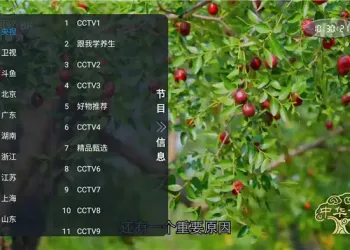 非凡TV直播 v1.0.2:电视直播软件介绍121 人气#开放实验室
非凡TV直播 v1.0.2:电视直播软件介绍121 人气#开放实验室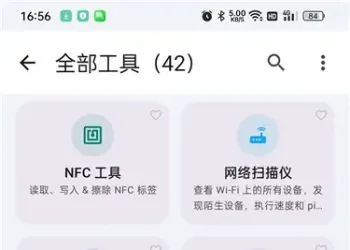 Wifi Share 工具箱 v5.16.4:手机实用工具133 人气#开放实验室
Wifi Share 工具箱 v5.16.4:手机实用工具133 人气#开放实验室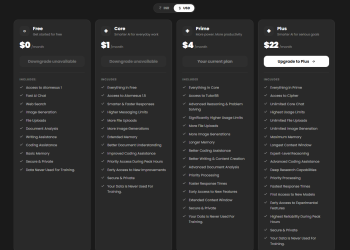 Atomesus AI模型:支持限时免费体验与开源140 人气#互联网服务
Atomesus AI模型:支持限时免费体验与开源140 人气#互联网服务

 admin
admin 52JinY 助手
52JinY 助手


 微信公众号
微信公众号 官方抖音号
官方抖音号