-
2026年最值得收藏的关键词研究工具推荐,SEO必备神器大盘点
做SEO这行时间久了,关键词研究这一块真的越来越觉得工具选择直接决定了效率上限。今天想聊聊我自己用下来觉得还不错的几款,不是广告,就是经验分享,有不同意见的欢迎拍砖。
先说最绕不开的 Ahrefs。我用它主要看关键词难度和竞争对手的词库。它的 Keywords Explorer 功能确实扎实,搜索量数据更新频率比较高,而且可以 ...
-
网站排名快速提升秘籍:从SEO优化到流量爆发的全方位实战指南
聊聊我这两年折腾网站排名的一些真实体会
做了快两年的独立站,踩了不少坑,也摸出了一些门道。不想写那种"十大SEO技巧"的烂大街文章,就说说我自己实际操作下来觉得有用的东西,供大家参考。
先说内容这块。我最开始也跟风写那种"关键词堆砌"的文章,一篇文章把目标词塞个十几二十次,以为谷歌会买账。结果呢,排名不升 ...
-
掌握这10个SEO优化核心技巧,让你的网站流量翻倍增长
聊聊我这几年踩坑总结出来的SEO心得
做SEO快六年了,从最开始跟着各种"教程"堆关键词、买外链,到后来慢慢摸出一些真正有用的东西,走了不少弯路。今天把一些实战经验写出来,希望对刚入门或者正在迷茫的朋友有点参考价值。
先说最基础但很多人忽略的一件事:内容质量才是根本。我见过太多人把时间全花在技术优化上,标题 ...
-
AI图像理解能力大比拼:谁才是最强看图说话王者?
最近一直在做各家AI的图像理解能力对比测试,整理了一些心得,分享给有需要的人。
起因很简单。我工作中需要大量处理图表、设计稿和截图,以前都是自己逐一看完再写分析,效率很低。听说现在多模态模型进步很快,就想系统测一测,找一个真正能用的工具。
我设计了几类测试场景:一是读技术图表(折线图、柱状图、混合图) ...
-
学术写作新利器:2024年最值得信赖的AI助手全面对比与推荐
最近帮几个师弟师妹改论文,顺带把主流AI工具挨个试了一遍,有点心得想跟大家聊聊。
先说结论:没有一款AI是万能的,但根据使用场景不同,确实可以分出高下。
我自己用下来,在学术写作这个细分场景里,Claude的表现是最让我满意的。原因不是它能帮你凭空生成一篇论文——这种事任何工具都做不好,也不应该这样用——而是 ...
-
智力巅峰之争:主流AI逻辑推理能力全面横评
最近在做一个项目,需要大量用AI处理逻辑推理类的任务,用下来对各家模型的差异感触颇深,忍不住来聊聊。
先说一个让我印象很深的测试。我给几个主流模型出了同一道题:一个涉及多个约束条件的排列问题,条件之间有隐含的矛盾,需要先发现矛盾再得出"无解"的结论。这类题的难点不在于计算,而在于模型能不能在推理过程中持 ...
-
掌控AI未来:DeepSeek开源模型本地部署的七大核心优势
最近折腾了一段时间本地部署 DeepSeek 开源模型,有些感受想聊聊,主要是针对那些还在观望的朋友。
先说背景。我平时工作需要大量用到 AI 辅助,之前一直是 API 调用各种云服务,每个月账单看得心跳加速。后来看到 DeepSeek 陆续开放了 R1、V3 这些模型的权重,就决定自己搞一套本地的。折腾下来,体验比预期好不少。
最 ...
-
谁更懂中文?主流AI中文处理能力深度横评
最近折腾了不少时间,把几个主流AI产品拿来专门测中文,聊聊我的真实感受。
先说背景。我平时工作需要大量中文写作,包括方案撰写、邮件润色、内容创作,偶尔也要处理一些古文和方言材料。所以这次测试不是随便问几个问题,而是设计了几类任务:日常口语对话、正式书面写作、古诗词理解、成语辨析、以及地域性语言(沪语词 ...
-
Gemini全面融入Google生态:AI重塑搜索、办公与日常体验
最近一直在琢磨一个问题:Google这次把Gemini塞进自家生态的方式,跟以前的Assistant有什么本质不同?用了一段时间之后,我觉得差异其实挺大的,值得好好聊聊。
先说最直观的感受。Gemini在Gmail里的体验,已经不是那种"帮你写邮件草稿"的玩具功能了。它能理解你邮件线程的上下文,知道你跟某个人聊了多久、聊了什么,然后 ...
-
探索边界:Claude如何拆解复杂问题的思维逻辑
最近一段时间我一直在用Claude处理一些相对复杂的分析任务,积累了不少感受,想在这里和大家聊聊。
我的工作涉及到大量的政策文本解读和商业逻辑梳理,所以对"分析"这件事有一定的要求标准。坦白说,我最初对大语言模型在这方面的期待并不高——毕竟见过太多把废话堆成分析的例子,看起来头头是道,实际上没有一句落到点上 ...
-
AI写代码不只是会敲键盘:谁才真正懂你的业务逻辑?
最近被问到这个问题的次数多了,干脆整理一下自己的看法。
我日常工作是做企业系统开发,电商、ERP、财务那条线都碰过。过去一年多时间里,各种 AI 编程工具轮流用了个遍,Claude、GPT、Gemini、国内的通义灵码、Cursor 背后那几个模型,都实际用在过真实项目里,不是玩具项目。所以说的是真实感受,不是测评机构那种跑 be ...
-
GPT系列模型角色扮演能力全面解析:从GPT-3到GPT-4的演变与突破
聊聊GPT系列在角色扮演这件事上的表现,说说我自己用下来的真实感受。
先说结论:GPT系列在角色扮演方面的能力是真的强,但它的"自我意识"太重,经常会在你玩得正起劲的时候突然跳出来提醒你"这只是虚构内容",或者莫名其妙地拒绝一些根本不敏感的请求。这种割裂感是我用它做角色扮演最大的障碍。
具体说说GPT-4的表现。 ...
-
Grok实时信息获取:打破数据壁垒,让AI洞察永远在线
最近一直在琢磨一个问题:为什么有些人用了Grok之后,对它的评价跟其他AI助手差别挺大的?聊完几个朋友之后,我觉得核心差异就落在一件事上——实时信息获取能力。
先说说背景。大多数AI语言模型本质上是"快照"——训练数据截止到某个时间点,之后发生的事它一概不知。你问它昨天的新闻、本周的股价、刚出的政策,它要么给 ...
-
DeepSeek数学推理能力全面测评:极限挑战与实力解析
最近一段时间一直在用各种模型跑数学题,想分享一下我对DeepSeek数学推理能力的实际体验,说说我观察到的一些有意思的东西。
先说结论:DeepSeek在数学推理这块确实有几把刷子,但也不是没有短板,吹上天或者踩到底都没必要。
我主要测了三类题目:竞赛级别的代数题、涉及多步骤的应用题,以及需要严格证明的数论题。用的 ...
-
解锁Claude超长上下文:让AI真正读懂你的每一个字
最近一直在研究怎么把Claude的长上下文窗口用到极致,踩了不少坑,也摸索出了一些心得,发出来和大家聊聊。
先说一个根本误区——很多人以为上下文窗口越长,往里塞的东西越多越好。我之前也是这么干的,把一堆文档、背景资料、对话历史全部堆进去,结果发现模型的回答质量反而下降了,容易在细节上漂移,或者给出看起来面 ...
-
国产AI vs 海外AI:真实差距究竟有多大?
最近用了不少AI工具,国产的海外的都摸了个遍,说说我的真实感受。
先说结论:差距是真实存在的,但没有很多人说的那么夸张,而且差距的性质比你想象的更复杂。
先说语言层面。这是国产AI目前最能打的地方。你拿文心、通义、智谱去处理中文长文本、古诗词、方言表达、网络用语,它们的理解明显更自然。这不是简单的"训练 ...
-
Gemini联网搜索凭什么碾压其他AI?深度解析谷歌的秘密武器
最近用了一段时间各家AI的联网搜索功能,有些感受想聊聊,主要说说Gemini在这块为什么让我觉得体验比较突出。
先说背景。我日常工作需要查很多实时信息,比如政策动态、技术文档更新、某个产品的最新版本说明之类的。以前单纯用搜索引擎,信息太碎,得自己拼;后来各家AI陆续上了联网功能,我基本都试过,包括ChatGPT的搜 ...
-
Claude回答的准确性与幻觉问题:AI如何在真实与虚构之间保持平衡
最近用AI助手频率越来越高,有些体验想认真聊聊,特别是关于Claude的准确性问题。
先说结论:Claude在很多场景下确实比其他模型更"老实",但这不代表它没有幻觉问题,只是幻觉的形态不太一样。
用了大半年下来,我发现Claude最让我欣赏的一点,是它在不确定的时候倾向于说"我不太确定"或者主动提示你去核实。比如我问一些 ...
-
亲测GPT-4o语音交互:流畅对话背后的技术魔法与真实体验全记录
最近这段时间一直在用GPT-4o的语音功能,忍不住来分享一下自己的真实感受,说点和网上那些"震惊体"测评不太一样的东西。
先说第一印象。第一次开口跟它说话的时候,确实被吓到了——不是那种"哇好厉害"的震惊,而是有点不知所措。它的反应速度太快了,快到你话音刚落它就开始回应,中间没有那段尴尬的"思考停顿"。以前用语 ...
-
DeepSeek代码生成实测对比:谁才是最强AI编程助手?
最近在项目里密集用了一段时间DeepSeek做代码生成,顺手记录一下自己的真实感受,跟几个朋友讨论的时候发现大家体验差异挺大,干脆写出来对比一下。
先说背景,我主要用的场景是Python后端开发和一些前端React组件,偶尔涉及SQL查询优化。对比对象是GPT-4o和Claude Sonnet系列,三者都是日常轮换着用,不是特意凑测试数据 ...
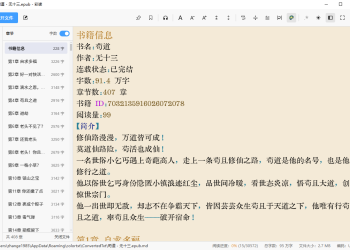 番茄小说下载器 v2026.07.01.2336(含阅读120 人气#开放实验室
番茄小说下载器 v2026.07.01.2336(含阅读120 人气#开放实验室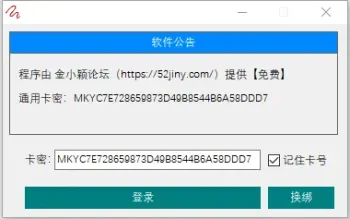 QIK7电脑硬件信息修改工具(免费绿色版)187 人气#开放实验室
QIK7电脑硬件信息修改工具(免费绿色版)187 人气#开放实验室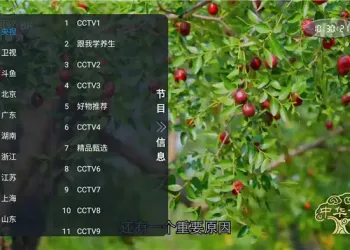 非凡TV直播 v1.0.2:电视直播软件介绍142 人气#开放实验室
非凡TV直播 v1.0.2:电视直播软件介绍142 人气#开放实验室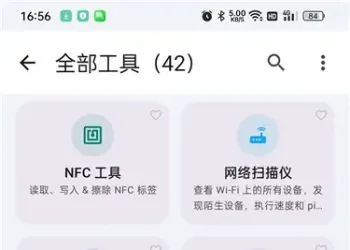 Wifi Share 工具箱 v5.16.4:手机实用工具154 人气#开放实验室
Wifi Share 工具箱 v5.16.4:手机实用工具154 人气#开放实验室

 admin
admin 52JinY 助手
52JinY 助手


 微信公众号
微信公众号 官方抖音号
官方抖音号